You have full access to this article via your institution.

Synthetic data have the potential to improve aspects of health care, for example, in the rapid analysis of X-rays.Credit: Costfoto/NurPhoto/Getty
The revolution promised by the application of artificial intelligence (AI) to research and health care has been much discussed, but less attention has been paid to the sub-revolution following in its slipstream. Increasingly, AI models are being trained on ‘synthetic’ data. There is no universally agreed definition for this type of data, but, in this Editorial, we are talking about information used in medical research that was not collected in the real world. A growing number of synthetic data sets exist that were generated by a mathematical model or algorithm — sometimes incorporating real-world data — and are designed to mimic the presumed statistical properties of real-world data.

AI-generated medical data can sidestep usual ethics review, universities say
The use of such data has some clear benefits, for example, for hypothesis generation, for preliminary testing of an idea before actual data collection, and for anticipating the results of experiments. Synthetic data also have much potential to improve studies involving low- and middle-income countries, where real data can be scarce, and barriers to collection high. Synthetic data can also be shared more freely, in part because there are fewer risks of study participants being identified, proponents say1.
As one example of their application in clinical settings, synthetic data are being used in AI models that can interpret patients’ X-ray scans and generate reference scans2. Worldwide, there is a shortage of radiologists, and real-world training data remain limited. The AI models can assist radiologists in making decisions, potentially helping them to work faster and with greater accuracy3.
As we report this week (Nature https://doi.org/10.1038/d41586-025-02911-1; 2025), some universities and research institutions are waiving ethical review requirements for research in which synthetic data are being used instead of human data. Ordinarily, an independent ethics board would review how studies affect participants’ rights, safety, dignity and well-being. But because synthetic data at most derive from human data, some researchers have been able to persuade their institutions that an ethical review isn’t needed. Considering the speed and scale at which AI is being adopted, this raises at least two concerns.

This AI ‘thinks’ like a human — after training on 160 psychology studie
The first is how to better understand and mitigate the risk that people whose data have been used to generate AI models could be identified. This particular problem might well lessen as models move through their second, third, fourth and fifth iterations — in which synthetic data are essentially trained on other synthetic data, and the link to real data becomes more remote. But it needs to be taken seriously if, for example, identities can be revealed without individuals’ consent4.
The second concern is more deeply rooted. Anyone with skin in this game — such as producers, publishers and users of AI studies — needs to be reassured that the findings of AI models trained on synthetic data can be validated, not least because of the risk of ‘model collapse’. In this scenario, AI models trained on successive generations of synthetic data start to generate nonsense5. Validation can take different forms, but at its core is the principle that a result needs to be confirmed by researchers independent of those reporting it. At present, this often does not happen, and there are no agreed guidelines for how it should. However, researchers are proposing ways in which it could be supported.
Zisis Kozlakidis, a data scientist for the World Health Organization, headquartered in Geneva, Switzerland, says that, in the absence of real-world data against which to test results from synthetic data, researchers should explain how they generated their synthetic data, describing their algorithm, parameters and assumptions. They could also propose how another group might validate their results.
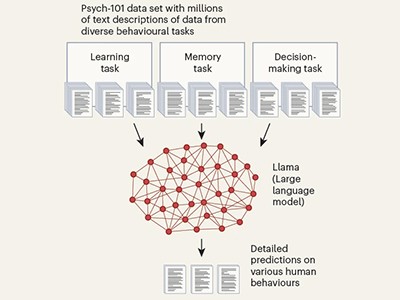
Could machine learning help to build a unified theory of cognition?
In an article published in BMJ Evidence-Based Medicine in July, bioinformatics researcher Randi Foraker at the University of Missouri in Columbia and her colleagues suggest that there should be reporting standards for synthetic data alongside those that already exist for data and code availability6. They recommend that researchers work with publishers to develop these.
Marcel Binz at the Helmholtz Institute for Human-Centred AI in Munich, Germany, makes a powerful case for validation across all forms of AI (Nature https://doi.org/g9r6ct; 2025), following a study, on which he is a co-author, on how AI is being used to predict people’s decision-making7. The model that he and his colleagues developed, called Centaur, was trained on data from psychology experiments that recorded more than 10 million choices made by study participants across a range of decision-making tasks. Some researchers are sceptical about its ability to predict human behaviour. Binz told Nature’s news team that the model — which is freely accessible — needs to be externally validated. “It’s probably the worst version of Centaur that we will ever have, and it will only get better from here.”
The benefits of synthetic data are clear. But the risks need to be recognized and mitigated — and the temptation to accept results as valid and accurate just because a computer says they are must be avoided at all costs.
Source link
