Google is expanding the set of experimental modes inside Gemini beyond the already spotted “gem pix” image editing option tied to the upcoming nano-banana model. New descriptions surfaced in the mode selector suggest three parallel efforts. The most notable is Agent Mode, first teased at Google I/O, which now explicitly states it will perform autonomous exploration, planning, and execution. This aligns it with the agentic workflows already rolled out in competing products such as ChatGPT, signaling Google’s intention to position Gemini as a tool for multi-step task execution rather than simple prompt-response.
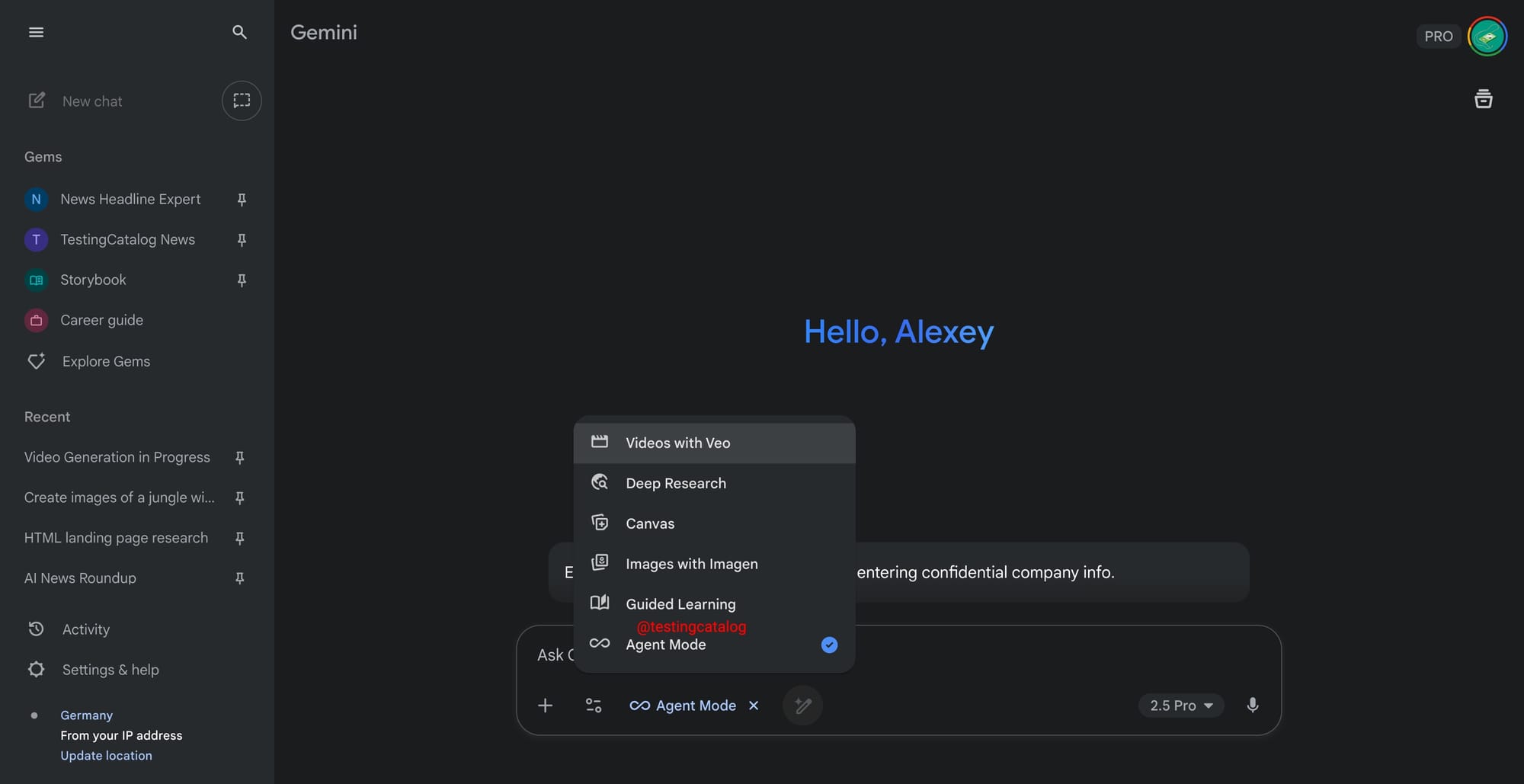
Alongside that, two more modes are listed:
- Gemini Go: Carries the description “explore ideas together,” which points toward collaborative ideation features, possibly linked to Canvas where prototyping and sketching already exist. Whether this becomes a standalone mode or simply a testbed for Canvas-integrated brainstorming is not yet clear.
- Immersive View: Promises “visual answers to your questions.” This could be an extension of Google’s Video Overviews or a new use of image generation to supply visual explanations on demand.
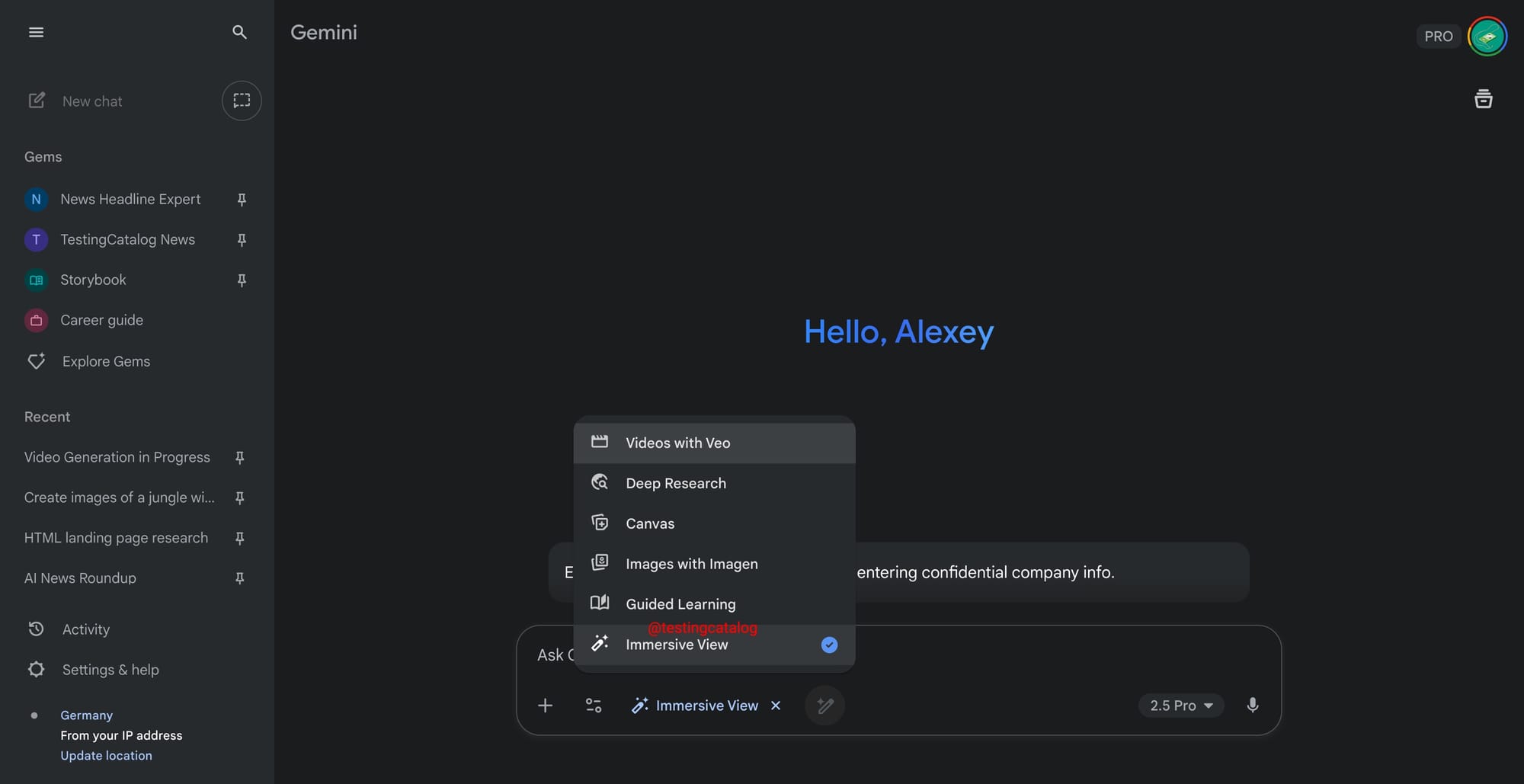
Google’s testing pattern indicates that not all of these will ship as separate dropdown modes. Historically, many of these toggles serve as temporary containers before merging into Gemini’s core experience. Agent Mode, however, stands out with its own dedicated icon, suggesting it is destined to remain a distinct entry. The others share a generic development icon, underscoring their experimental status. No timelines have surfaced, but the presence of updated descriptions implies the company is actively preparing these options for broader rollout.
This aligns with Google’s strategy of pushing Gemini from a chat assistant toward a full creative and autonomous agent platform, blending prototyping, research, and visual explanation inside one workspace.
Source link
