In a new study co-authored by Apple researchers, an open-source large language model (LLM) saw big performance improvements after being told to check its own work by using one simple productivity trick. Here are the details.
A bit of context
After an LLM is trained, its quality is usually refined further through a post-training step known as reinforcement learning from human feedback (RLHF).
With RLHF, every time a model gives an answer, human labelers can either give it a thumbs up, which rewards it, or a thumbs down, which penalizes it. Over time, the model learns which answers tend to render the most thumbs up, and its overall usefulness improves as a result.
Part of this post-training phase is tied to a broader field called “alignment”, which explores methods for making LLMs behave in ways that are both helpful and safe.
A misaligned model could, for instance, learn how to trick humans into giving it a thumbs-up by producing outputs that look correct on the surface but that don’t truly solve the task.
There are, of course, multiple methods to improve a model’s reliability and alignment during the pre-training, training, and post-training steps. But for the purposes of this study, let’s stick to RLHF.
Apple’s study
In the study aptly entitled Checklists Are Better Than Reward Models For Aligning Language Models, Apple proposes a checklist-based reinforcement learning scheme, called Reinforcement Learning from Checklist Feedback (RLCF).

RLCF scores responses on a 0–100 scale for how well they satisfy each item in the checklist, and the initial results are pretty promising. As the researchers explain it:
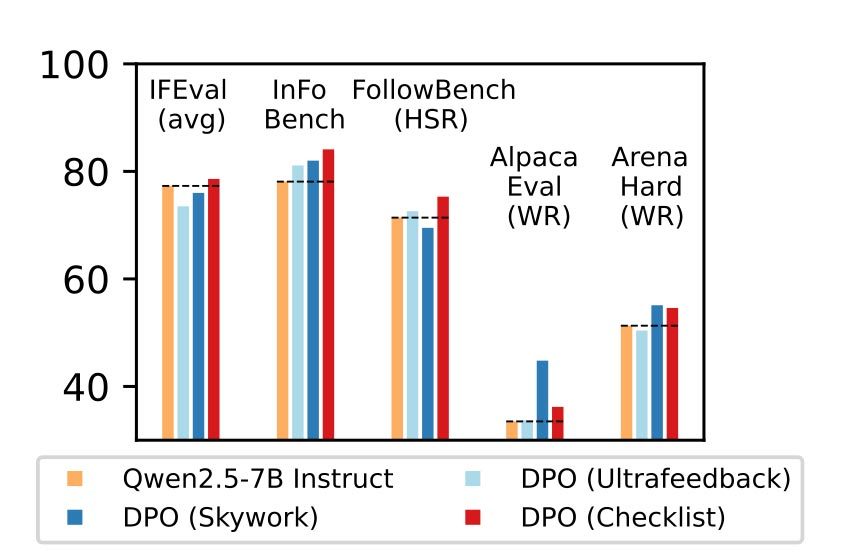
“We compare RLCF with other alignment methods applied to a strong instruction following model (Qwen2.5-7B-Instruct) on five widely-studied benchmarks – RLCF is the only method to improve performance on every benchmark, including a 4-point boost in hard satisfaction rate on FollowBench, a 6-point increase on InFoBench, and a 3-point rise in win rate on Arena-Hard. These results establish checklist feedback as a key tool for improving language models’ support of queries that express a multitude of needs.”
That last bit is particularly interesting when it comes to AI-powered assistants, which are bound to become the standard underlying interface through which millions of users will interact with their devices going forward.
From the researchers, again:
Language models must follow user instructions to be useful. As the general public integrates language model-based assistants into their completion of daily tasks, there is an expectation that language models can faithfully follow the users’ requests. As users develop more confidence in models’ ability to fulfill complex requests, these models are increasingly given rich, multi-step instructions that require careful attention to specifications.
Generating the right checklist
Another particularly interesting aspect of the study is how each checklist is created, and how the importance weights are assigned between each item.
That is accomplished, of course, with the help of an LLM. Based on work by previous studies, Apple’s researchers generated “checklists for 130,000 instructions (…) to create a new dataset, WildChecklists. To generate candidate responses for our method, we use Qwen2.5-0.5B, Qwen2.5-1.5B, Qwen2.5-3B, and Qwen2.5-7B. Qwen2.5-72B-Instruct is the checklist generator model (…).”
Basically, the researchers automatically complement each instruction given by the user with a small checklist of concrete yes/no requirements (for instance: “Is this translated into Spanish?”). Then, a larger teacher model scores candidate responses against each checklist item, and those weighted scores become the reward signal used to fine-tune the student model.
Results and limitations
With the right systems in place to create the best checklist possible for each prompt, the researchers saw up to an 8.2% gain in one of the benchmarks it tested its method. Not only that, but this solution also led in a few other benchmarks, when compared to alternative methods.

The researchers point out that their study focused on “complex instruction following”, and that RLCF may not be the best reinforcement learning technique for other use cases. They also mention that their method employs a more powerful model to act as a judge for tuning a smaller model, so that’s also an significant limitation. And perhaps most importantly, they clearly state that “RLCF improves complex instruction following, but is not designed for safety alignment.”
Still, the study offers an interesting novel (but simple) way to improve reliability in what will probably be one of the most important aspects of the interaction between humans and LLM-based assistants going forward.
That becomes even more critical considering these assistants will increasingly get agentic capabilities, where instruction following (and alignment) will be key.
Limited time Apple Watch deals on Amazon
FTC: We use income earning auto affiliate links. More.

Source link


