
The second presentation on today’s graphics track comes from NVIDIA. Like AMD, NVIDIA is mid-cycle on its current generation of graphics products, having launched the first of them back in late 2024. As a result, their Hot Chips presentation is more of a recap, with a focus on what the Blackwell architecture offers for graphics – and particularly for the field of machine learning-based neural rendering.
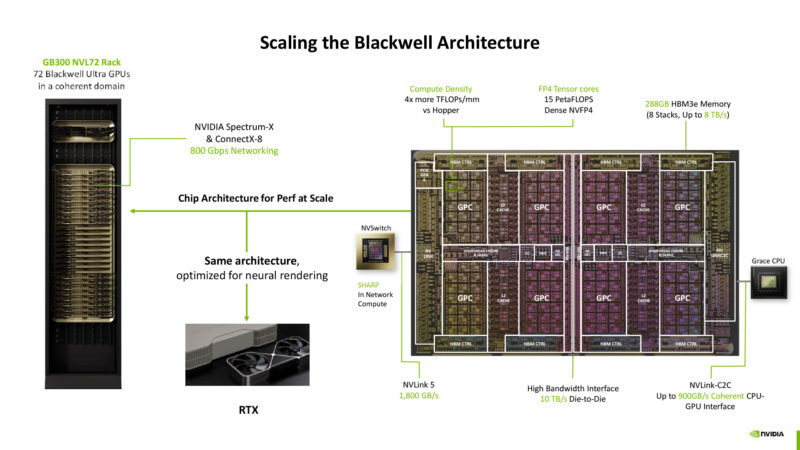
NVIDIA designed the Blackwell architecture to scale from datacenter to mobile. In some respects, AI is AI – whether it’s generating tokens for ChatGPT, or performing neural denoising for raytracing. As a result, NVIDIA is able to scale up and down as they need for professional and consumer GPUs. With Blackwell, NVIDIA is betting hard on FP4 ML compute in order to maximize performance.

The big focus of this talk: neural rendering. Using machine learning to help generate frames. NVIDIA wants to get over the uncanny valley – a task that would require a ridiculous amount of additional compute in traditional rasterization. But ML techniques can potentially get there sooner.
NVIDIA has a bit of hammer perspective here. Even 7 years after the launch of Turing, they’re still trying to sell audiences on all the different things that machine learning can do. So it’s not just about graphics, but it’s about using this kind of scaling to conserve power in laptops, and using ML agents within the games themselves.

Blackwell, in turn, has several improvements to boost ML performance. All the while boosting efficiency to try to ensure that every SM has something useful to work on every cycle. Be it graphics or various kinds of ML models. There’s a whole AI management processor to help keep data moving and SMs filled.
None the less, there’s still a lot of raw horsepower being thrown out here. 360 RT TFLOPs of RT performance, GDDR7 memory, and so, so many tensor FLOPS.
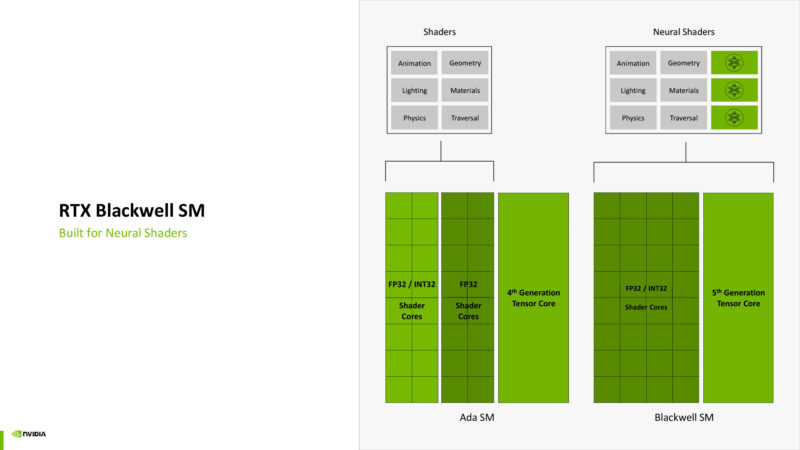
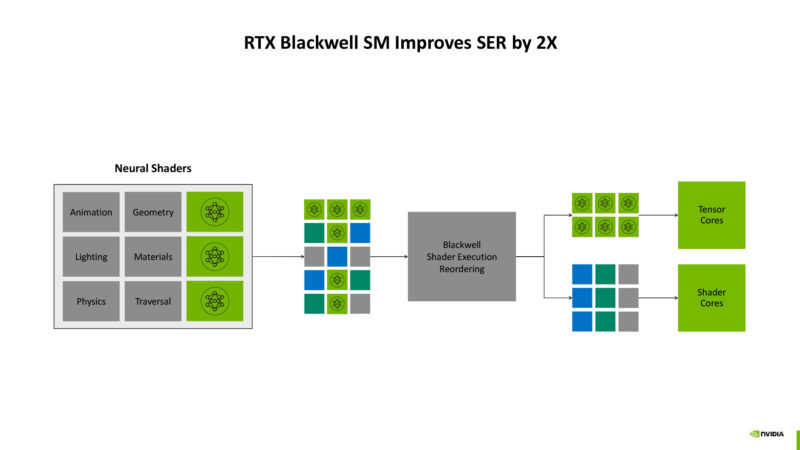
NVIDIA makes significant use of shader execution reordering in order to help keep their SMs filled. Re-order work to avoid bubbles to keep things moving. This is a combination of software and hardware. There’s apparently a lot of integer math going on here just to do this sorting, which is why integer performance was a big deal for NVIDIA in the Blackwell generation.
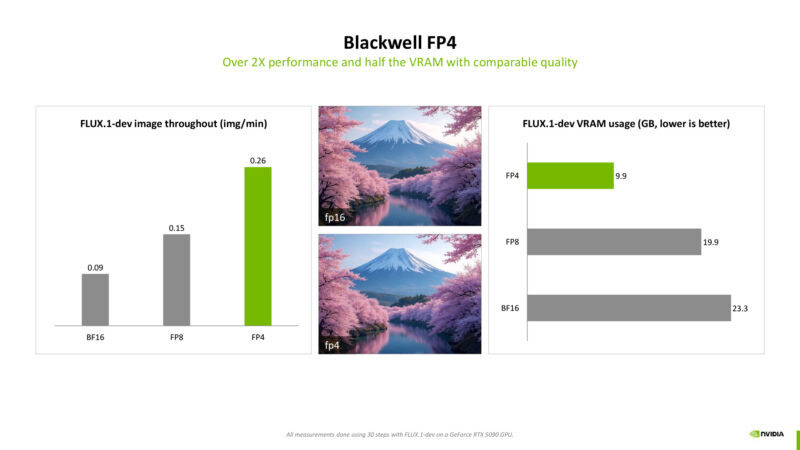
NVIDIA is going big on FP4. They expect it to still be able to deliver the necessary accuracy in graphics models, while consuming half the memory and half the compute resources. Side note: FP4 has a much wider dynamic range than INT4, which can have some further benefits.
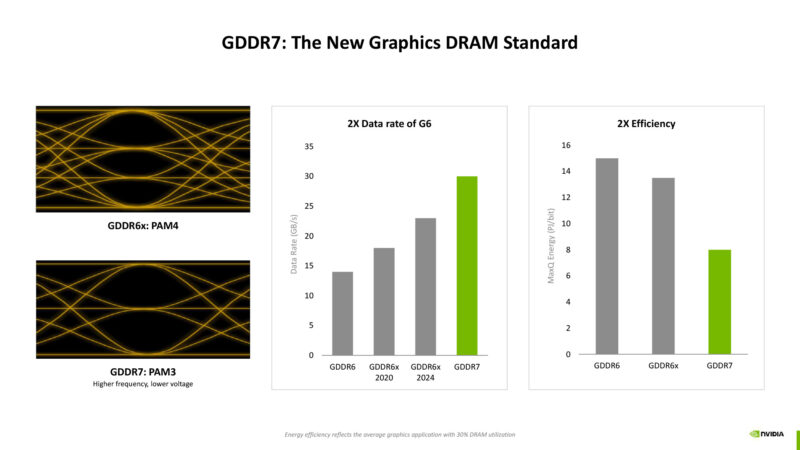
Blackwell added GDDR7 support, which brought a notably jump in total memory bandwidth. Versus PAM4 (GDDR6X), PAM3 offers fewer bits per clock, but the higher SNR allows for much higher clockspeeds, more than offsetting the difference. It also allows for lower voltages.
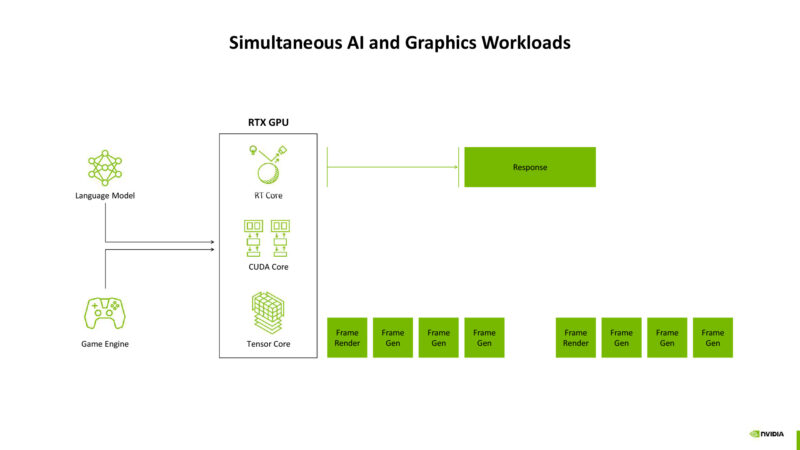
NVIDIA wants to get the time to first token down, especially in mixed graphics/ML workloads. Basically laying the groundwork for making ML models/AI agents more usable for interactive gaming.
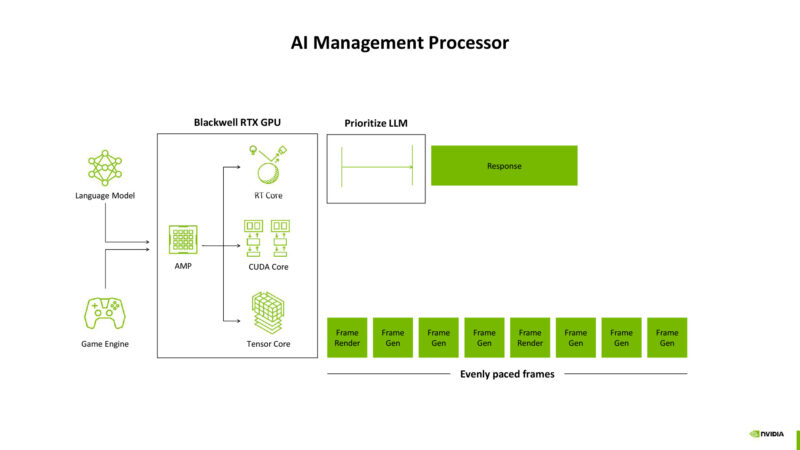
The AI management processor is a big part in this, helping to orchestrate work to interleave graphics and ML without stalling out the GPU with expensive context switches.
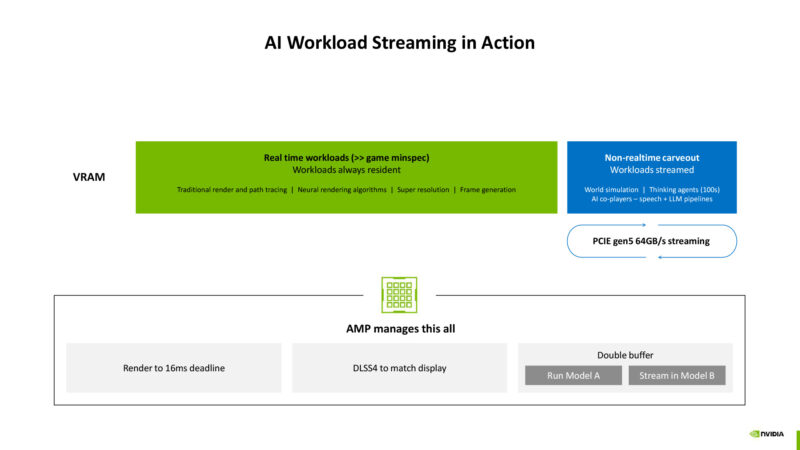
The scheduling needs are complex, especially with different workloads having different latency requirements. ML agents don’t have quite the same deadline as real-time graphics, for example. These are things the AI management processor needs to take into account.
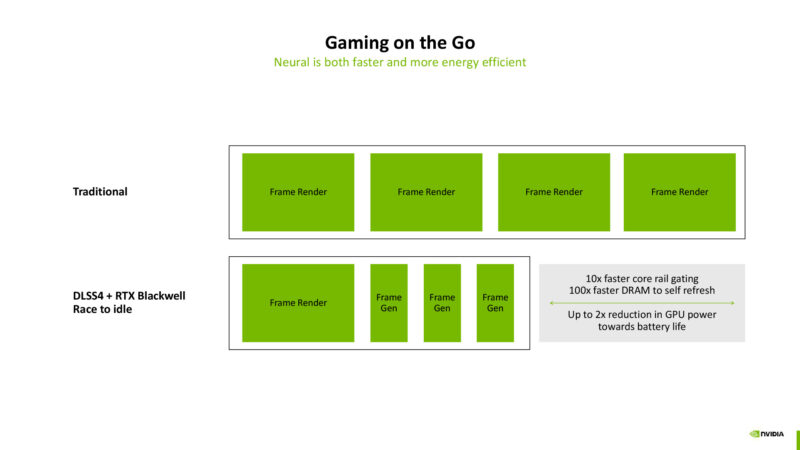
Frame generation: skip spending power on rendering a frame, and replace it with an interpolated frame for a fraction of the power cost. Up to 2x reduction in power consumed.
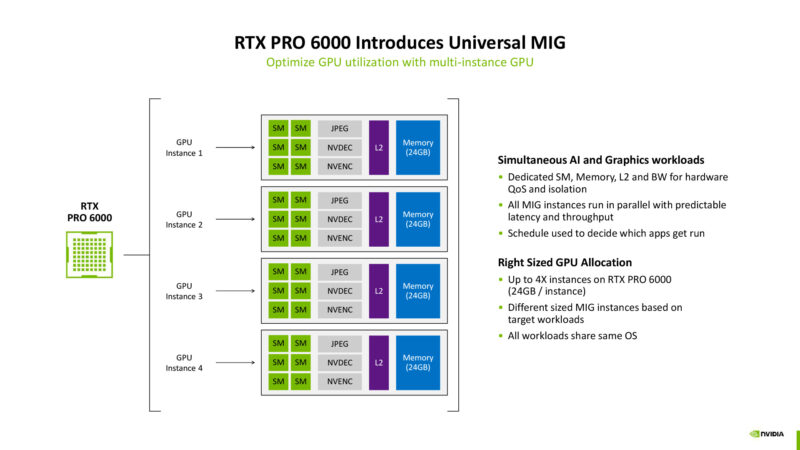
Graphics Blackwell also supports Universal MIG (Multi-instance GPU), which was previously a datacenter GPU-only feature. This improves on splitting up a graphics GPU for multiple clients, such as a streaming service, by allocating each client a different set of SMs.
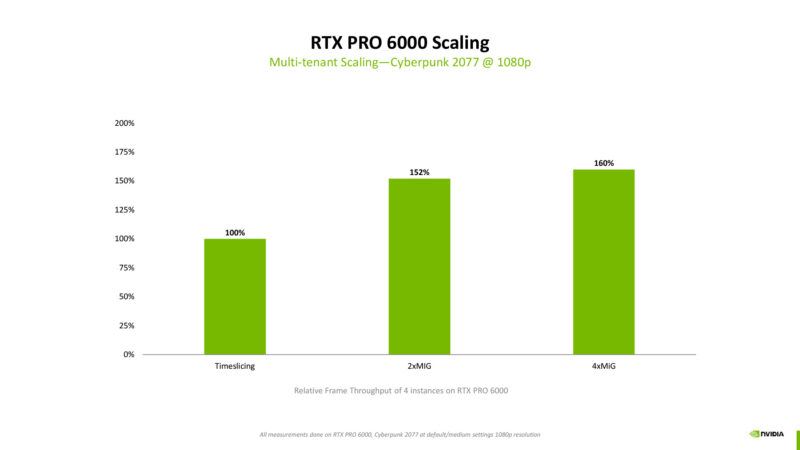
Compared to naive time slicing, NVIDIA is seeing up to 60% better performance from MIG. The gains come from the fact that a single 1080p client workload is too small to fully saturate a full RTX Pro 6000; splitting it up into smaller vGPUs keeps the GPUs saturated with work by executing multiple workloads in parallel.

Source link
:max_bytes(150000):strip_icc()/GettyImages-2231344336-7896931d52c04abfb99345f52496e52f.jpg "After Months of Calm, Nvidia Earnings Could Spark a Big Stock Market Move")